

Benefits
Specifications
How-to
Contact Us
Learn More

Introducing
•
TRU EVAL
Evaluation
that’s actually reliable
Run structured, repeatable model evaluations that catch issues before they reach production. Because your AI's reliability shouldn't be a guessing game.

Introducing TruEval

68%
of users stop using AI products after one bad experience
Source: Enterprise AI Adoption Report 2025
3x
higher compliance violation risk for unevaluated AI systems
Source: EU AI Act Compliance Analysis
$2.1M
avg cost of AI-related live incident
Source: Gartner AI Risk Study
40%
of engineering time spent on manual AI testing
Source: State of MLOps 2026
Solution
A Better Way to Evaluate AI
TruEval provides structured, repeatable evaluation infrastructure that scales with your AI ambitions. Here's how we're different.
Automated at Scale
Run or schedule thousands of evaluations automatically.
TruEval runs comprehensive test suites across your entire AI system in minutes, not weeks. Every code change, every model update, every prompt modification gets evaluated against your full test battery automatically.

Quantitatively Measured
Real Metrics, no gut feelings.
Get concrete numbers for accuracy, hallucination rate, safety, robustness, and 100+ other metrics. Track performance over time, compare models, and know exactly how changes impact quality.

Compliance-Ready
Real Metrics, no gut feelings.
Every evaluation is logged, versioned, and traceable. Generate compliance reports automatically. Prove to regulators that your AI meets safety and quality standards with hard evidence.
Testing AI is fundamentally different from testing traditional software.


AI RISK


REDUCED
01
Unreliable Output
- Hallucinations
- Accuracy Issues
REDUCED
02
Compliance Gaps
- Regulatory fines
- Security breaches
REDUCED
03
Production Incidents
- Lost user trust
- Incident response
REDUCED
04
Wasted Resources
- Engineering & QA costs
- Incident response
Solution
Three Steps to Reliable AI
TRU EVAL provides structured, repeatable evaluation infrastructure that scales with your AI ambitions. Here's how we're different.
1
Connect your AI Application
Step 1
Any model, any provider, any architecture.
Integrate via API or SDK
Connect LLMs, RAG systems, voice models, or agentic applications using simple API endpoints or SDK integrations
Support for Modern AI Frameworks
Works with popular agentic frameworks, custom pipelines, and proprietary systems—anything that accepts inputs and produces outputs.
2
Build Your Test Suite
Step 2
Design evaluations tailored to your application.
Prompt-Based Test Scenarios
Create modular prompts to test reasoning, safety, instructions, and real-world use cases.
Datasets for Structured Testing
Use curated datasets or import your own to evaluate models across diverse inputs and edge cases.
3
Run Evaluation
Step 2
Turn AI behavior into measurable insights.
Failure Analysis & Metrics
Identify exactly where models fail with granular metrics and traceable evaluation results.
Detailed Evaluation Reports
Generate comprehensive reports highlighting performance, safety issues, and model reliability.

Structured Prompt Intelligence
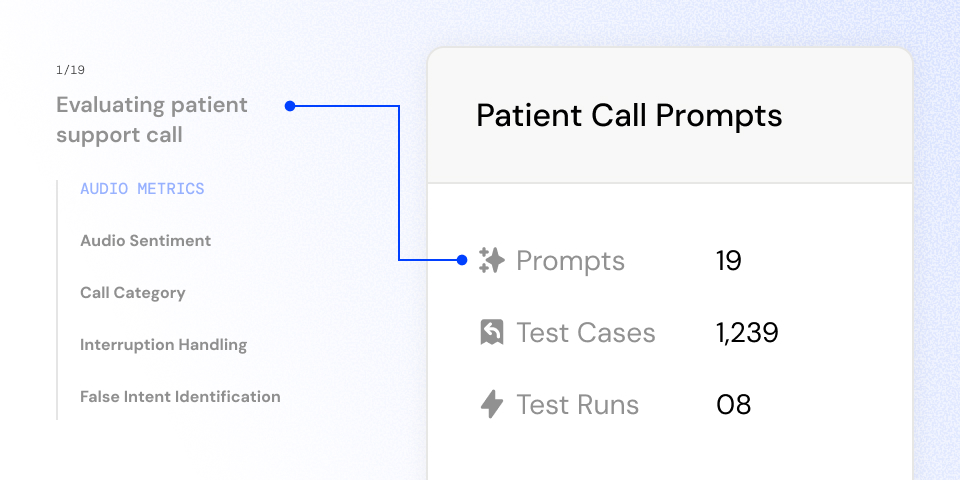
Build, manage, and reuse evaluation prompts across projects. Trusys includes a conversational scenario builder to simulate multi-turn interactions, enabling teams to test real user journeys, agent behaviors, and complex reasoning workflows.

Design multi-turn conversations and realistic interaction flows to test agentic and chat-based systems.
Create, organize, and reuse prompts across evaluation projects.
Standardize evaluation prompts across teams and model versions.
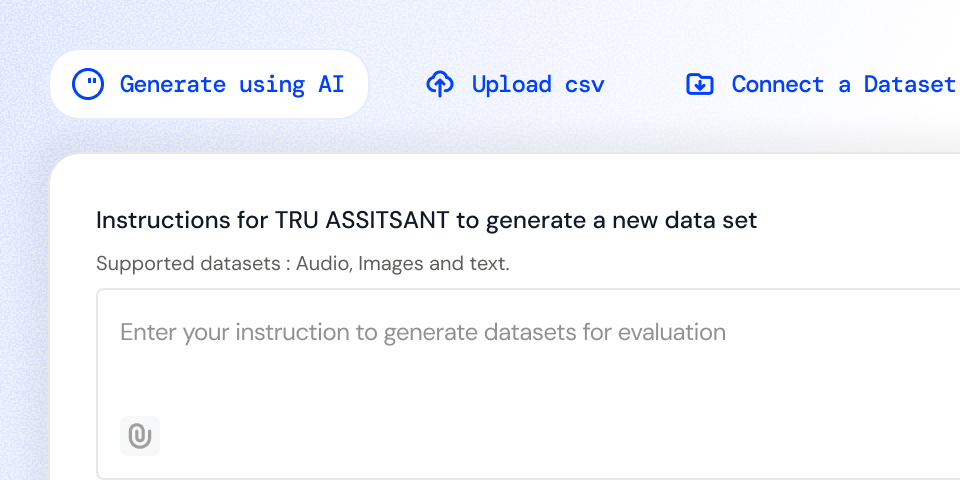
AI- Powered Dataset Generation
Import datasets, generate synthetic evaluation data, or build structured test suites inside the platform. Design datasets for edge cases, adversarial prompts, and real-world user scenarios.
Upload CSVs, connect external datasets, or build structured evaluation sets within the platform
Automatically generate diverse test data including text inputs, conversations, and voice datasets.
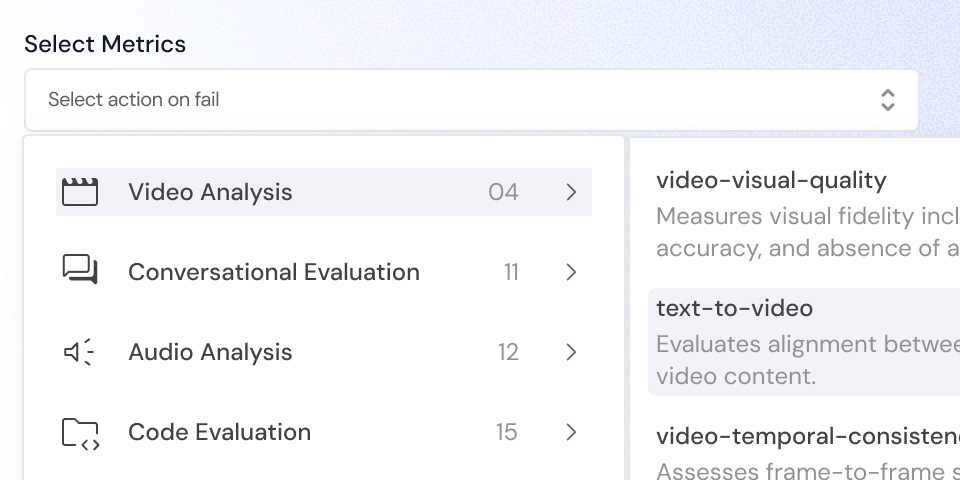
Rich Evaluation Metrics
Analyze AI systems using advanced metrics for hallucination detection, bias, safety violations, reasoning quality, latency, and reliability—tailored for LLMs, RAG systems, voice models, and multimodal AI applications.
Support metrics tailored for RAG systems, voice models, conversational AI, and multimodal applications.
Rich Evaluation Metrics
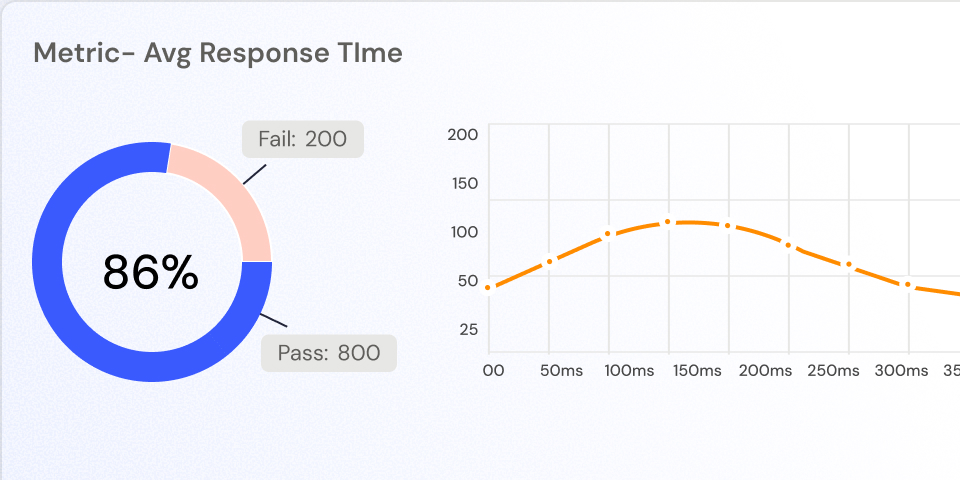
Evaluation Reports
Visualize evaluation outcomes with detailed reports highlighting performance trends, failure patterns, safety violations, and reliability risks—so teams know exactly what to fix before deployment.
Comprehensive Performance Reports
Pinpoint problematic prompts, unsafe outputs, and reliability issues with insights.
The Difference
The Trusys Advantage
The gap between teams using structured evaluation and those relying on manual processes is growing every day. Here's the reality.
Testing & Evaluation
Metric

Without Trusys

With Trusys
Test Coverage

Manual testing of 10-20 prompts

1000+ automated test cases across all scenarios
Evaluation Speed
Days or weeks per model update
Minutes for comprehensive evaluation
Repeatability
Different results each time
Identical tests, comparable results over time
Consistency
Subjective "looks good" assessments
Quantitative metrics with benchmarks

Risk & Reliability
Metric
Without Trusys
With Trusys
Production Incidents
High - issues discovered by users
93% reduction in production incidents
Hallucination Detection
No systematic checking
Automated detection across all outputs
Edge Case Coverage
Missed until users find them
Adversarial testing built-in
Model Drift Monitoring
No visibility until complaints
Continuous monitoring with alerts

Cost & ROI
Metric
Without Trusys
With Trusys
Testing Infrastructure
Custom scripts = tech debt
Managed platform, always up-to-date
Incident Costs
$2.1M average per incident
Prevent before production
Compliance Fines Risk
Up to €35M or 7% revenue
Demonstrable compliance
Resource Efficiency
Senior engineers on QA work
Engineers building value




Team Productivity
Metric
Without Trusys
With Trusys
Engineering Time
40% spent on manual testing
Automated - focus on building features
Deployment Frequency
Monthly due to testing bottlenecks
Daily or multiple times per day
Time to Market
Months of validation delays
6 months faster to production
Team Collaboration
Siloed, inconsistent approaches
Shared metrics, unified workflow
The choice is clear
Manual testing and ad-hoc evaluation worked when AI was experimental. But as AI becomes mission-critical, the teams with systematic evaluation infrastructure will dominate their markets.
10x
Faster to market
93%
Fewer incidents
100%
Audit ready
Trust & Security
Built for Enterprise Security Standard
Your AI evaluation infrastructure needs to be as secure and compliant as your production systems. TruEval is built with enterprise requirements in mind.

Enterprise-Grade Security
SOC 2 Type II certified. Your evaluation data is encrypted at rest and in transit.

Data Privacy First
Your prompts, datasets, and results stay in your environment. We never train on your data.

Global Compliance
GDPR, HIPAA, SOC 2 compliant. Built for regulated industries from day one.

Audit-Ready Documentation
Every evaluation is logged and versioned. Generate compliance reports on demand.






Flexible deployment options

Cloud-Hosted
Fully managed SaaS platform. Start evaluating in minutes.

On-Premise
Self-hosted in your data center. Maximum security and compliance.
Stop guessing.
Start measuring.
Join teams building reliable AI with TruEval. Start with a free trial, no credit card required. Get your first evaluation running in under 10 minutes.
Questions about TRU EVAL?
Our team is here to help. Schedule a personalized demo to see how TRU EVAL fits your specific use case.
Book a Demo

Ready to dive in?
Check out our documentation and tutorials. Get started with example datasets and evaluation templates.
Start Free Trial
Free Trial
No credit card required
10 Min
To first evaluation
24/7
Enterprise support

Introducing
•
TRU EVAL
Evaluation
that’s actually reliable
Run structured, repeatable model evaluations that catch issues before they reach production. Because your AI's reliability shouldn't be a guessing game.
68%
of users stop using AI products after one bad experience
Source: Enterprise AI Adoption Report 2025
3x
higher compliance violation risk for unevaluated AI systems
Source: EU AI Act Compliance Analysis
$2.1M
avg cost of AI-related live incident
Source: Gartner AI Risk Study
40%
of engineering time spent on manual AI testing
Source: State of MLOps 2026
Solution
A Better Way to Evaluate AI
TruEval provides structured, repeatable evaluation infrastructure that scales with your AI ambitions. Here's how we're different.
Automated at Scale
Run or schedule thousands of evaluations automatically.
TruEval runs comprehensive test suites across your entire AI system in minutes, not weeks. Every code change, every model update, every prompt modification gets evaluated against your full test battery automatically.
Quantitatively Measured
Real Metrics, no gut feelings.
Get concrete numbers for accuracy, hallucination rate, safety, robustness, and 100+ other metrics. Track performance over time, compare models, and know exactly how changes impact quality.
Compliance-Ready
Real Metrics, no gut feelings.
Every evaluation is logged, versioned, and traceable. Generate compliance reports automatically. Prove to regulators that your AI meets safety and quality standards with hard evidence.
Testing AI is fundamentally different from testing traditional software.
AI RISK
REDUCED
01
Unreliable Output
- Hallucinations
- Accuracy Issues
REDUCED
02
Compliance Gaps
- Regulatory fines
- Security breaches
REDUCED
03
Production Incidents
- Lost user trust
- Incident response
REDUCED
04
Wasted Resources
- Engineering & QA costs
- Incident response
Solution
Three Steps to Reliable AI
TRU EVAL provides structured, repeatable evaluation infrastructure that scales with your AI ambitions. Here's how we're different.
1
Connect your AI Application
Step 1
Any model, any provider, any architecture.
Integrate via API or SDK
Connect LLMs, RAG systems, voice models, or agentic applications using simple API endpoints or SDK integrations
Support for Modern AI Frameworks
Works with popular agentic frameworks, custom pipelines, and proprietary systems—anything that accepts inputs and produces outputs.
2
Build Your Test Suite
Step 2
Design evaluations tailored to your application.
Prompt-Based Test Scenarios
Create modular prompts to test reasoning, safety, instructions, and real-world use cases.
Datasets for Structured Testing
Use curated datasets or import your own to evaluate models across diverse inputs and edge cases.
3
Run Evaluation
Step 2
Turn AI behavior into measurable insights.
Failure Analysis & Metrics
Identify exactly where models fail with granular metrics and traceable evaluation results.
Detailed Evaluation Reports
Generate comprehensive reports highlighting performance, safety issues, and model reliability.

Structured Prompt Intelligence
Build, manage, and reuse evaluation prompts across projects. Trusys includes a conversational scenario builder to simulate multi-turn interactions, enabling teams to test real user journeys, agent behaviors, and complex reasoning workflows.
Design multi-turn conversations and realistic interaction flows to test agentic and chat-based systems.
Create, organize, and reuse prompts across evaluation projects.
Standardize evaluation prompts across teams and model versions.
AI- Powered Dataset Generation
Import datasets, generate synthetic evaluation data, or build structured test suites inside the platform. Design datasets for edge cases, adversarial prompts, and real-world user scenarios.
Upload CSVs, connect external datasets, or build structured evaluation sets within the platform
Automatically generate diverse test data including text inputs, conversations, and voice datasets.
Rich Evaluation Metrics
Analyze AI systems using advanced metrics for hallucination detection, bias, safety violations, reasoning quality, latency, and reliability—tailored for LLMs, RAG systems, voice models, and multimodal AI applications.
Support metrics tailored for RAG systems, voice models, conversational AI, and multimodal applications.
Rich Evaluation Metrics
Evaluation Reports
Visualize evaluation outcomes with detailed reports highlighting performance trends, failure patterns, safety violations, and reliability risks—so teams know exactly what to fix before deployment.
Comprehensive Performance Reports
Pinpoint problematic prompts, unsafe outputs, and reliability issues with insights.
The Difference
The Trusys Advantage
The gap between teams using structured evaluation and those relying on manual processes is growing every day. Here's the reality.
Testing & Evaluation
Metric
Without Trusys
With Trusys
Test Coverage
Manual testing of 10-20 prompts
1000+ automated test cases across all scenarios
Evaluation Speed
Days or weeks per model update
Minutes for comprehensive evaluation
Repeatability
Different results each time
Identical tests, comparable results over time
Consistency
Subjective "looks good" assessments
Quantitative metrics with benchmarks
Risk & Reliability
Metric
Without Trusys
With Trusys
Production Incidents
High - issues discovered by users
93% reduction in production incidents
Hallucination Detection
No systematic checking
Automated detection across all outputs
Edge Case Coverage
Missed until users find them
Adversarial testing built-in
Model Drift Monitoring
No visibility until complaints
Continuous monitoring with alerts
Cost & ROI
Metric
Without Trusys
With Trusys
Testing Infrastructure
Custom scripts = tech debt
Managed platform, always up-to-date
Incident Costs
$2.1M average per incident
Prevent before production
Compliance Fines Risk
Up to €35M or 7% revenue
Demonstrable compliance
Resource Efficiency
Senior engineers on QA work
Engineers building value
Team Productivity
Metric
Without Trusys
With Trusys
Engineering Time
40% spent on manual testing
Automated - focus on building features
Deployment Frequency
Monthly due to testing bottlenecks
Daily or multiple times per day
Time to Market
Months of validation delays
6 months faster to production
Team Collaboration
Siloed, inconsistent approaches
Shared metrics, unified workflow
The choice is clear
Manual testing and ad-hoc evaluation worked when AI was experimental. But as AI becomes mission-critical, the teams with systematic evaluation infrastructure will dominate their markets.
10x
Faster to market
93%
Fewer incidents
100%
Audit ready
Trust & Security
Built for Enterprise Security Standard
Your AI evaluation infrastructure needs to be as secure and compliant as your production systems. TruEval is built with enterprise requirements in mind.
Enterprise-Grade Security
SOC 2 Type II certified. Your evaluation data is encrypted at rest and in transit.
Data Privacy First
Your prompts, datasets, and results stay in your environment. We never train on your data.
Global Compliance
GDPR, HIPAA, SOC 2 compliant. Built for regulated industries from day one.
Audit-Ready Documentation
Every evaluation is logged and versioned. Generate compliance reports on demand.
Flexible deployment options
Cloud-Hosted
Fully managed SaaS platform. Start evaluating in minutes.
On-Premise
Self-hosted in your data center. Maximum security and compliance.
Stop guessing.
Start measuring.
Join teams building reliable AI with TruEval. Start with a free trial, no credit card required. Get your first evaluation running in under 10 minutes.
Questions about TRU EVAL?
Our team is here to help. Schedule a personalized demo to see how TRU EVAL fits your specific use case.
Book a Demo
Ready to dive in?
Check out our documentation and tutorials. Get started with example datasets and evaluation templates.
Start Free Trial
Free Trial
No credit card required
10 Min
To first evaluation
24/7
Enterprise support