Format-Preserving Encryption (FPE) enables privacy-preserving analytics and AI by encrypting sensitive spans while preserving schema, regex shape, and field constraints. We detail cryptographic underpinnings (FF1), engineering patterns for RAG/prompt pipelines, and a token-slicing method that protects PII at character/subword granularity without collapsing model context. We also outline Trusys integrations across evaluation (Tru-Eval), monitoring (Tru-Pulse), and guardrails.
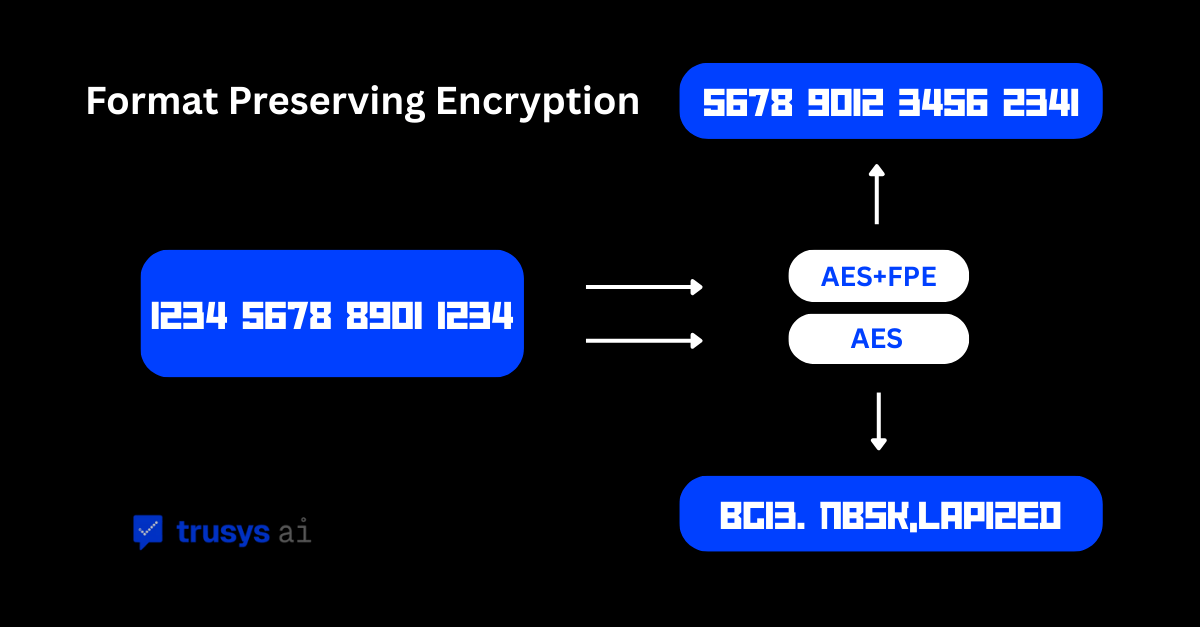
1) What FPE is—and isn’t
- Definition: An encryption mode that maps a value within a constrained domain (digits, alphanumerics, date formats, etc.) to another value in the same domain. Typically built as a tweakable Feistel construction over AES (FF1/FF3 families).
- Current standard status: NIST SP 800-38G Rev.1 focuses on FF1; earlier variants (FF3, FF3-1) faced cryptanalytic concerns, and recent drafts remove FF3. For production, prefer FF1 with correct domain sizing and tweaks.
- Not tokenization: Tokenization substitutes a lookup token; FPE produces ciphertext that still “looks like” the original (same length/charset), enabling equality joins and validation without detokenization. Many orgs deploy both: tokenization for storage scope reduction, FPE for operational analytics/AI flows.
2) Cryptographic sketch (FF1)
- Primitive: AES as a PRP; FF1 is a radix-aware Feistel network over the domain Σ^n (e.g., digits 0-9 of length n).
- Tweak: Non-secret associated data (e.g., tenant_id|field|salt) that binds ciphertext to context and thwarts cross-dataset linkability.
- Security notes:
- Ensure sufficiently large domains (NIST now requires larger domains).
- Avoid low-entropy domains (e.g., tiny name sets) without additional defenses (peppered tweaks, rate-limits).
- Use approved parameters; don’t roll your own FPE.
3) Why FPE matters in AI systems
- Schema-preserving pipelines: You can encrypt PANs, Aadhaar, SSNs, DOB, emails, phones, addresses—yet keep schemas, regex validators, and legacy ETL intact.
- Deterministic joins & analytics: Because FPE is deterministic per key+tweak, equality filters and group-bys still work (e.g., “same person across logs”), without exposing raw PII.
- RAG/search compatibility: If you encrypt sensitive spans consistently, you can encrypt the user’s query spans the same way to retrieve relevant chunks, then decrypt just-in-time for authorized viewers.
- Prompt privacy: Pre-encrypt sensitive spans before they leave your boundary (SaaS LLM/API), then decrypt post-inference internally.
4) “Token slicing” with FPE (LLM-aware protection)
Goal: Protect only the sensitive slices—characters or subword tokens—so (a) the model still sees useful context, (b) prompt length doesn’t bloat, and (c) referential integrity is preserved.
Three practical strategies:
- Character-class FPE (regex domains):
- Phone \d{10}, Aadhaar \d{12}, PAN [A-Z]{5}\d{4}[A-Z]{1}, etc. Encrypt only those spans using FF1 over the matching alphabet. Model still sees surrounding words normally.
- Subword-aware slicing (BPE/WordPiece):
- Identify entity spans (NER or rules), then FPE just those subword tokens or characters. This keeps context tokens intact while protecting identifiers. (Understanding BPE’s merge behavior helps decide whether to slice per-char or per-token.)
- Hybrid placeholders + FPE tags:
- Replace name → @PERS_[FPE("Ravi", tweak)]. Keeps a human-readable placeholder and a deterministic surrogate for joins. Useful when the tokenizer might otherwise split encrypted text unfavorably.
Trade-offs:
- Encrypting inside a word can push it off vocabulary. To mitigate, constrain the FPE alphabet to common tokenizable glyphs (e.g., lowercase a-z or digits).
- Encrypting too much reduces semantic utility of embeddings; encrypt only PII spans that don’t carry task semantics.
5) RAG & embedding patterns
- Index path: Pre-encrypt detected PII → store encrypted spans in the raw text and in metadata fields.
- Query path: Detect PII in the user query → encrypt those spans with the same key+tweak → search → decrypt results for authorized users or keep encrypted for analytics.
- Do not embed raw secret values; embeddings leak signal. For identity-centric search (“find records for +91-9876543210”), encrypt the query’s phone before retrieval, then rely on metadata filters or sparse signals.
6) Key management & ops
- Keys: Per-tenant keys via cloud KMS/HSM; envelope encryption for FPE keys; rotate with versioned tweaks.
- Tweaks: Derive (HKDF(keyID | tenantID | field | purpose | epoch)); change epochs to limit linkage.
- Observability: Emit OpenTelemetry spans—who/what/why (non-sensitive metadata), latency, success/fail; integrate with SIEM.
- Performance: AES-FF1 adds micro- to low-millisecond overhead per span depending on domain length—generally negligible compared to network/LLM latency.
7) Security pitfalls & mitigations
- Low-entropy domains (e.g., short name lists): Add peppered tweaks, throttle lookups, or combine with keyed hashing for joins.
- Domain sizing: Respect NIST domain constraints; avoid tiny domains that invite brute force.
- Algorithm selection: Use FF1 (per NIST Rev.1 direction) with vetted libraries; avoid legacy FF3/FF3-1 paths.
8) Trusys reference architecture
- Pre-ingest: Presidio-style PII detection → Trusys Tru-Guard calls Trusys FPE Engine (FF1 over approved alphabets) → emits encrypted text + tags.
- RAG: Index encrypted spans; the Trusys Retriever Adapter applies the same FPE transform to PII inside queries before hitting vector/keyword stores.
- Prompt firewalls: Trusys SDK interceptors encrypt sensitive spans on the way out to third-party LLMs; decrypt responses on the way back.
- Evaluation & monitoring: Tru-Eval generates red-team tests that probe for leakage around encrypted spans; Tru-Pulse provides OTel-based traces and alerts when decrypted spans appear in logs.
- Governance: Policy maps (what gets FPE vs masking vs tokenization), KMS integration, auditable tweak derivations, revocation/rotation drills.
9) Worked mini-examples (illustrative)
- Phone (India):
- Plain: +91 98765 43210
- FPE(FF1, tweak=tenant|phone|v2): +91 59217 80436 (same format/length)
- DOB (ISO date; domain-constrained):
- Plain: 1987-05-21 → FPE: 1996-03-14 (valid YYYY-MM-DD)
- Email (local-part only; preserve domain):
- Plain: ravi.kumar@company.in → q3v3.njma@company.in
- Token slicing in a prompt:
- Plain: “Call Ravi at +91-9876543210 about invoice INV-4309.”
Sliced+FPE: “Call @PERS_njma at +91-5921780436 about invoice INV-5801.” (context remains; identifiers protected)