What is AI Model Drift — and Why Catching It Early Saves You from Silent Failures in Production
Written by

Your fraud detection model passed every pre-deployment benchmark. It scored 96% accuracy in testing, sailed through your MLOps pipeline, and went live without incident. Six months later, it's quietly approving fraudulent transactions it would have once flagged instantly — and nobody noticed until a compliance audit.
This is model drift in machine learning. It's the most common, most underestimated failure mode in production AI. Unlike a system crash, drift gives you no error logs, no alerts, and no obvious signal that something has gone wrong.
In this guide, we break down exactly what model drift is, why it happens, how to detect it early, and how platforms like Trusys.ai (https://trusys.ai) are built to catch it before silent failures become loud disasters.
Key Statistics
- 91% of ML models experience measurable performance degradation within 12 months of deployment.
- 68% of model failures in production go undetected for more than 30 days.
- It costs 3x more to fix drift after it causes downstream business damage vs. catching it early.
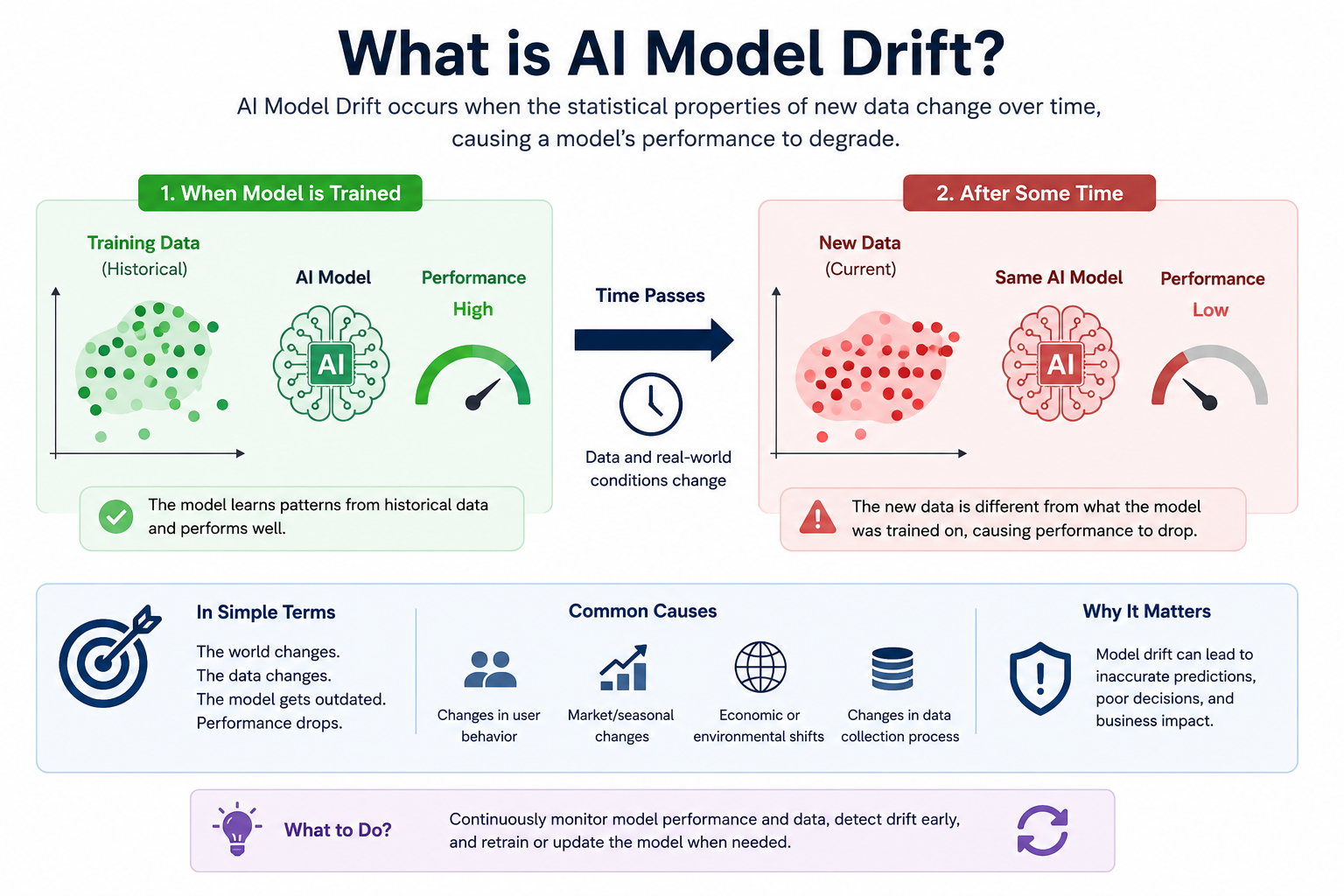
What is Model Drift in Machine Learning?
Model drift (also called AI model degradation) occurs when a machine learning model's real-world performance declines over time because the world it was trained on no longer matches the world it operates in. The model's parameters haven't changed — but the relationship between inputs and correct outputs has.
Think of it like a map drawn in 2019 being used to navigate a city in 2026. The streets look familiar, but new roads, renamed districts, and demolished landmarks make the map progressively less reliable. The map is technically the same — but the territory has drifted.

Key definition: Model drift in machine learning refers to the degradation of a model's predictive performance caused by changes in the statistical properties of input data, the target variable, or the relationship between the two — occurring after the model has been deployed to production.
The 4 Main Types of Model Drift
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Behavioural Drift in Agentic AI
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.

Real-World Impact: What Drift Actually Costs
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Why Does Model Drift Happen? Root Causes
Why Rate Limit Failures Are So Dangerous
Many organizations still treat rate limit errors as minor API inconveniences.
That assumption is becoming expensive.
In reality, rate limit failures create cascading operational disruption across the enterprise.
How to Detect Model Drift in Machine Learning
Why Rate Limit Failures Are So Dangerous
Many organizations still treat rate limit errors as minor API inconveniences.
That assumption is becoming expensive.
In reality, rate limit failures create cascading operational disruption across the enterprise.
The Drift Lifecycle: From Invisible to Catastrophic
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Why Point-in-Time Testing Isn't Enough
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Model Drift Management: Best Practices
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Conclusion: Drift Is Inevitable. Damage Is Not.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Model Drift and AI Governance
Model drift in machine learning isn't just a technical problem — it's a governance problem. Regulators under the EU AI Act, NIST AI RMF, and sector-specific frameworks (FINRA, FDA, FCA) are increasingly treating model degradation as a compliance risk, not just an engineering concern.
AI systems classified as high-risk under the EU AI Act are required to undergo ongoing post-market monitoring — which effectively mandates systematic drift detection as a regulatory obligation, not a best practice.
Conclusion: Drift Is Inevitable. Damage Is Not.
Every model deployed to production will drift. That's not a deficiency of the model or the team — it's the fundamental nature of deploying a statistical approximation of the world into a world that keeps changing.
What separates teams that manage drift well from teams that don't isn't the absence of drift — it's the speed of detection and the strength of remediation infrastructure. Catching model drift in machine learning at Phase 1, before it accumulates and compounds, is the difference between a routine model update and a production incident.
The tools and practices exist. The monitoring frameworks are mature. The only remaining question is whether your organisation has made continuous AI assurance an operational priority — or whether you're still relying on pre-deployment testing and hoping the world holds still.
It won't. But with the right observability infrastructure, that's fine.
FAQs
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Stop guessing.
Start measuring.
Join teams building reliable AI with TruEval. Start with a free trial, no credit card required. Get your first evaluation running in under 10 minutes.
Questions about Trusys?
Our team is here to help. Schedule a personalized demo to see how Trusys fits your specific use case.
Book a Demo

Ready to dive in?
Check out our documentation and tutorials. Get started with example datasets and evaluation templates.
Start Free Trial
Free Trial
No credit card required
10 Min
To first evaluation
24/7
Enterprise support


Benefits
Specifications
How-to
Contact Us
Learn More

What is AI Model Drift — and Why Catching It Early Saves You from Silent Failures in Production
Written by
Your fraud detection model passed every pre-deployment benchmark. It scored 96% accuracy in testing, sailed through your MLOps pipeline, and went live without incident. Six months later, it's quietly approving fraudulent transactions it would have once flagged instantly — and nobody noticed until a compliance audit.
This is model drift in machine learning. It's the most common, most underestimated failure mode in production AI. Unlike a system crash, drift gives you no error logs, no alerts, and no obvious signal that something has gone wrong.
In this guide, we break down exactly what model drift is, why it happens, how to detect it early, and how platforms like Trusys.ai (https://trusys.ai) are built to catch it before silent failures become loud disasters.
Key Statistics
- 91% of ML models experience measurable performance degradation within 12 months of deployment.
- 68% of model failures in production go undetected for more than 30 days.
- It costs 3x more to fix drift after it causes downstream business damage vs. catching it early.
What is Model Drift in Machine Learning?
Model drift (also called AI model degradation) occurs when a machine learning model's real-world performance declines over time because the world it was trained on no longer matches the world it operates in. The model's parameters haven't changed — but the relationship between inputs and correct outputs has.
Think of it like a map drawn in 2019 being used to navigate a city in 2026. The streets look familiar, but new roads, renamed districts, and demolished landmarks make the map progressively less reliable. The map is technically the same — but the territory has drifted.

Key definition: Model drift in machine learning refers to the degradation of a model's predictive performance caused by changes in the statistical properties of input data, the target variable, or the relationship between the two — occurring after the model has been deployed to production.
The 4 Main Types of Model Drift
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Behavioural Drift in Agentic AI
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.

Real-World Impact: What Drift Actually Costs
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Why Does Model Drift Happen? Root Causes
Why Rate Limit Failures Are So Dangerous
Many organizations still treat rate limit errors as minor API inconveniences.
That assumption is becoming expensive.
In reality, rate limit failures create cascading operational disruption across the enterprise.
How to Detect Model Drift in Machine Learning
Why Rate Limit Failures Are So Dangerous
Many organizations still treat rate limit errors as minor API inconveniences.
That assumption is becoming expensive.
In reality, rate limit failures create cascading operational disruption across the enterprise.
The Drift Lifecycle: From Invisible to Catastrophic
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Why Point-in-Time Testing Isn't Enough
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Model Drift Management: Best Practices
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Conclusion: Drift Is Inevitable. Damage Is Not.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Model Drift and AI Governance
Model drift in machine learning isn't just a technical problem — it's a governance problem. Regulators under the EU AI Act, NIST AI RMF, and sector-specific frameworks (FINRA, FDA, FCA) are increasingly treating model degradation as a compliance risk, not just an engineering concern.
AI systems classified as high-risk under the EU AI Act are required to undergo ongoing post-market monitoring — which effectively mandates systematic drift detection as a regulatory obligation, not a best practice.
Conclusion: Drift Is Inevitable. Damage Is Not.
Every model deployed to production will drift. That's not a deficiency of the model or the team — it's the fundamental nature of deploying a statistical approximation of the world into a world that keeps changing.
What separates teams that manage drift well from teams that don't isn't the absence of drift — it's the speed of detection and the strength of remediation infrastructure. Catching model drift in machine learning at Phase 1, before it accumulates and compounds, is the difference between a routine model update and a production incident.
The tools and practices exist. The monitoring frameworks are mature. The only remaining question is whether your organisation has made continuous AI assurance an operational priority — or whether you're still relying on pre-deployment testing and hoping the world holds still.
It won't. But with the right observability infrastructure, that's fine.
FAQs
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
AI Agents Multiply Infrastructure Load
AI agents introduce an entirely new scaling challenge.
Unlike a traditional user making one request at a time, AI agents may:
- Trigger multiple chained prompts
- Query several models simultaneously
- Retry failed requests autonomously
- Launch recursive workflows
One user action can suddenly generate dozens of inference operations.
Without workload controls, traffic amplification becomes unavoidable.
Stop guessing.
Start measuring.
Join teams building reliable AI with TruEval. Start with a free trial, no credit card required. Get your first evaluation running in under 10 minutes.
Questions about Trusys?
Our team is here to help. Schedule a personalized demo to see how Trusys fits your specific use case.
Book a Demo
Ready to dive in?
Check out our documentation and tutorials. Get started with example datasets and evaluation templates.
Start Free Trial
Free Trial
No credit card required
10 Min
To first evaluation
24/7
Enterprise support
What is AI Model Drift — and Why Catching It Early Saves You from Silent Failures in Production
Written by
Manish Tewari
Published on
May 27 2026
Your fraud detection model passed every pre-deployment benchmark. It scored 96% accuracy in testing, sailed through your MLOps pipeline, and went live without incident. Six months later, it's quietly approving fraudulent transactions it would have once flagged instantly — and nobody noticed until a compliance audit.
This is model drift in machine learning. It's the most common, most underestimated failure mode in production AI. Unlike a system crash, drift gives you no error logs, no alerts, and no obvious signal that something has gone wrong.
In this guide, we break down exactly what model drift is, why it happens, how to detect it early, and how platforms like Trusys.ai (https://trusys.ai) are built to catch it before silent failures become loud disasters.

Key Statistics
- 91% of ML models experience measurable performance degradation within 12 months of deployment.
- 68% of model failures in production go undetected for more than 30 days.
- It costs 3x more to fix drift after it causes downstream business damage vs. catching it early.

What is Model Drift in Machine Learning?
Model drift (also called AI model degradation) occurs when a machine learning model's real-world performance declines over time because the world it was trained on no longer matches the world it operates in. The model's parameters haven't changed — but the relationship between inputs and correct outputs has.
Think of it like a map drawn in 2019 being used to navigate a city in 2026. The streets look familiar, but new roads, renamed districts, and demolished landmarks make the map progressively less reliable. The map is technically the same — but the territory has drifted.
Key definition: Model drift in machine learning refers to the degradation of a model's predictive performance caused by changes in the statistical properties of input data, the target variable, or the relationship between the two — occurring after the model has been deployed to production.
The 4 Main Types of Model Drift
Not all drift is the same. Understanding the type of drift affecting your system is critical for applying the right detection and mitigation strategy.
1. Data Drift (Covariate Shift)
The distribution of input features P(X) changes. Example: customer age distribution shifts after a new market expansion. Detection difficulty: medium — statistical tests can flag it.
2. Concept Drift
The relationship between inputs and target P(Y|X) changes. Example: what constitutes 'fraudulent' behaviour changes post-pandemic. Detection difficulty: high — requires ground truth labels.
3. Label Drift (Prior Probability Shift)
The distribution of the target variable P(Y) changes. Example: approval rate for loan applications shifts due to policy changes. Detection difficulty: medium-high.
4. Prediction Drift
The distribution of model outputs P(Ŷ) changes. Example: a recommendation engine starts pushing the same 10 items to everyone. Detection difficulty: low — directly observable.
Behavioural Drift in Agentic AI
Beyond classical ML, modern agentic AI systems face a fifth, more dangerous type: behavioural drift. This is when an AI agent's decision patterns, personality, or tool-use strategies shift silently as memory accumulates manipulated content or as upstream model updates propagate. Trusys's TruPulse product was specifically built to detect this — tracing every agent action with full lineage to catch behavioural drift the moment it appears in production. (https://trusys.ai)
Why Does Model Drift Happen? Root Causes
Model drift in machine learning isn't a bug — it's the natural consequence of deploying a static model into a dynamic world. Common root causes:
- Seasonal and cyclical patterns: Models trained on summer purchasing behaviour perform poorly in winter. Models trained pre-2020 often fail to account for pandemic-era behavioural shifts.
- Data pipeline changes: Upstream schema updates, sensor recalibrations, or ETL logic changes silently alter the statistical properties of input features.
- Population shifts: Market expansion, demographic changes, or product pivots mean the model is suddenly scoring users it was never trained to understand.
- Competitive and regulatory changes: What constitutes 'spam', 'fraud', or 'creditworthy' evolves as adversaries adapt and regulations shift.
- Model feedback loops: A model's own predictions influence future training data — creating self-reinforcing biases that compound over time.
- LLM and foundation model updates: If your application depends on an underlying foundation model that gets updated, your downstream behaviour changes whether you changed anything or not.
The silent failure problem: Drift rarely triggers alerts. Your infrastructure health checks are green. Your API latency is fine. Your model is returning predictions confidently. The only signal is in the quality of those predictions — and that requires active monitoring, not passive observation.
Real-World Impact: What Drift Actually Costs
Healthcare A diagnostic AI trained on pre-2020 clinical data began systematically misclassifying certain presentations after treatment protocols changed. Clinicians noticed months later — not because of model alerts, but because a physician questioned an unexpected cluster of recommendations. See full case study: https://www.trusys.ai/blog-details/a-healthcare-ai-misdiagnosed-cases-after-model-driftcontinuous-oversight-from-tru-scout-by-trusys
Financial Services A fraud detection model in a mid-sized bank failed to adapt to a new category of synthetic identity fraud that emerged after COVID-era relief programmes. Fraud losses crept upward over 4 months before the drift was traced back to model degradation. See: https://www.trusys.ai/blog-details/financial-institution-ai-fraud-tru-scout-prevents-ai-failure
Banking Chatbots Interest rate changes caused a customer-facing banking chatbot to surface outdated product recommendations. See: https://www.trusys.ai/blog-details/banking-chatbot-wrong-interest-rates-tru-scout-ai-output-auditinga-banking-chatbot-offered-wrong-int
Manufacturing A computer vision model classifying product defects began misclassifying edge-case defects after a machinery upgrade changed the visual properties of outputs. Production halted. See: https://www.trusys.ai/blog-details/ai-failure-in-manufacturing
How to Detect Model Drift in Machine Learning
Detecting drift early requires a layered monitoring strategy. No single signal is sufficient.
Statistical Distribution Monitoring
Track statistical properties of incoming features over time using methods like the Kolmogorov-Smirnov test, Population Stability Index (PSI), or Jensen-Shannon divergence. A significant shift from training distributions is an early warning sign of data drift. This is a necessary but not sufficient condition — statistical shift in inputs doesn't always cause performance degradation, and performance can degrade without obvious input distribution changes (concept drift).
Performance Metric Tracking
When ground truth labels are available (even with delay), track live model performance against a baseline: accuracy, F1, AUC-ROC, RMSE, or whatever metric governs your use case. A monotonically declining trend is the clearest signal of drift. Challenge: in many real-world deployments, ground truth labels arrive late or never — making this reactive rather than proactive.
Output Distribution Monitoring
Track the distribution of model predictions over time. A fraud model returning 3% fraud flags shifting to 1% without a business explanation is a signal. These don't require labels and are immediately observable.
Shadow and Champion/Challenger Models
Run a newer candidate model in shadow mode alongside the production model. Systematic divergence in outputs — especially if the challenger's outputs correlate better with ground truth — is a reliable drift detection signal.
Embedding and Representation Drift
For LLM-based applications, monitor the drift in embedding space. If the semantic centroid of inputs your model is seeing shifts significantly from the training distribution, your model is operating in territory it was never trained to handle reliably.
Best practice: Combine multiple detection methods in a layered stack. Statistical drift monitors catch early signals; performance tracking confirms degradation; output distribution monitoring provides a label-free proxy. Together, they create overlapping coverage that no single method can provide alone.
The Drift Lifecycle: From Invisible to Catastrophic
Phase 1: Silent Onset (Weeks 1–4)
Statistical properties of incoming data begin to shift. Model performance starts degrading marginally — within noise. No alerts fire. Business KPIs are unaffected. This is the ideal detection window.
Phase 2: Accumulating Error (Weeks 4–12)
Degradation becomes systematic. Certain edge cases are consistently mispredicted. A/B tests or champion/challenger monitoring would now show divergence. Business metrics begin to show unexplained micro-trends.
Phase 3: Visible Degradation (Months 3–6)
Human operators begin noticing anomalies. Customer complaints increase. Business metrics show a clear downward trend. Debugging begins — but causation is hard to establish. Remediation timelines are now measured in weeks.
Phase 4: Production Failure (Month 6+)
The model has failed at scale. Incident response activates. Emergency retraining or rollback is required. Regulatory, financial, and reputational damage has occurred. Remediation cost is 3–10x what early intervention would have been.
Why Point-in-Time Testing Isn't Enough
Most teams validate models before deployment — and then assume the job is done. Pre-deployment testing is necessary but fundamentally insufficient for detecting drift. Here's why:
- Tests are static; the world is dynamic. A benchmark suite reflects the world at the time it was created. As the world changes, the benchmark becomes less representative.
- Drift is non-linear. Data distributions can be stable for months and then shift dramatically in days (economic shocks, viral events, regulatory changes). Quarterly retraining cycles can't respond to these dynamics.
- Drift is domain-specific. A model can degrade on a specific customer segment, product category, or geographic region while appearing healthy in aggregate metrics. Only granular, continuous monitoring reveals this.
This is precisely the thesis behind Trusys's position on AI governance: AI governance is not a one-time audit. See: https://www.trusys.ai/ai-governance-not-a-one-time-audit
Model Drift Management: Best Practices
- Define drift thresholds before deployment, not after an incident. Agree with stakeholders on what level of performance degradation triggers an alert, a review, or an emergency retrain.
- Monitor input features and outputs separately. Input drift doesn't always mean output degradation — and vice versa. Both are worth watching independently.
- Segment your monitoring. Aggregate metrics hide drift in sub-populations. Monitor performance by customer segment, geography, product category, and any dimension that matters to your business.
- Invest in ground truth pipelines. The more quickly you can label production predictions, the faster you can detect concept drift. Even sampling 5% of outputs for human review dramatically improves drift sensitivity.
- Treat retraining as a continuous process, not an event. Build infrastructure for rapid model updates, champion/challenger testing, and staged rollouts.
- Document your model cards and training data provenance. When drift occurs, you need to trace the cause. See: https://www.trusys.ai/blog-details/monitoring-ai-models-post-deployment-key-metrics-to-track
Model Drift and AI Governance
Model drift in machine learning isn't just a technical problem — it's a governance problem. Regulators under the EU AI Act, NIST AI RMF, and sector-specific frameworks (FINRA, FDA, FCA) are increasingly treating model degradation as a compliance risk, not just an engineering concern.
AI systems classified as high-risk under the EU AI Act are required to undergo ongoing post-market monitoring — which effectively mandates systematic drift detection as a regulatory obligation, not a best practice.
Conclusion: Drift Is Inevitable. Damage Is Not.
Every model deployed to production will drift. That's not a deficiency of the model or the team — it's the fundamental nature of deploying a statistical approximation of the world into a world that keeps changing.
What separates teams that manage drift well from teams that don't isn't the absence of drift — it's the speed of detection and the strength of remediation infrastructure. Catching model drift in machine learning at Phase 1, before it accumulates and compounds, is the difference between a routine model update and a production incident.
The tools and practices exist. The monitoring frameworks are mature. The only remaining question is whether your organisation has made continuous AI assurance an operational priority — or whether you're still relying on pre-deployment testing and hoping the world holds still.
It won't. But with the right observability infrastructure, that's fine.
Conclusion: Drift Is Inevitable. Damage Is Not.
- How can enterprises predict AI infrastructure bottlenecks before outages occur?
Enterprises can predict bottlenecks using AI observability tools that monitor token throughput, queue saturation, request concurrency, and inference latency in real time. Predictive traffic modeling and capacity forecasting also help teams anticipate scaling issues before users are impacted.
- What is token throughput in LLM infrastructure?
Token throughput refers to the number of input and output tokens an AI system can process within a given time frame. High token throughput is essential for maintaining fast response times during peak enterprise AI usage.
- What is AI workload isolation?
AI workload isolation separates different AI operations — such as customer-facing applications, internal experimentation, and batch jobs — into isolated infrastructure layers. This prevents one overloaded workflow from affecting critical enterprise AI services.
- Why is AI observability different from traditional application monitoring?
Traditional monitoring focuses on CPU, memory, and request latency. AI observability requires additional telemetry such as token usage, model latency, queue depth, inference throughput, retry frequency, and provider health metrics.
FAQs
- What is model drift in machine learning?
Model drift is the gradual decline in a deployed ML model's performance caused by changes in real-world data or behaviour that no longer match the conditions the model was trained on.
- What is the difference between data drift and concept drift?
Data drift is when the statistical distribution of input features changes. Concept drift is when the relationship between inputs and the correct output changes — even if the inputs look the same. Concept drift is harder to detect because it requires ground truth labels.
- How do you detect model drift in production?
Common methods include statistical distribution tests (KS test, PSI), tracking output distributions over time, monitoring live performance metrics against a baseline, running shadow/challenger models, and embedding drift analysis for LLM-based systems.
- How often should ML models be retrained to prevent drift?
There's no universal schedule — it depends on how fast your data environment changes. High-velocity domains (fraud, finance, social media) may need weekly or even continuous retraining. The better approach is trigger-based retraining: retrain when monitoring detects meaningful drift, not on a fixed calendar.
- What industries are most affected by model drift?
Financial services (fraud detection, credit scoring), healthcare (diagnostics, clinical decision support), manufacturing (defect detection), and any business using customer-facing AI (chatbots, recommendation engines) are particularly exposed because their data environments change frequently.
- Can model drift happen in LLMs and generative AI?
Yes. LLM-based applications can experience behavioural drift when the underlying foundation model is updated, when retrieval sources (RAG) change, or when accumulated memory is manipulated. This is sometimes called behavioural drift and is harder to detect than classical statistical drift.
- What is the cost of not monitoring for model drift?
Undetected drift leads to silent failures — poor predictions that look fine on your dashboards. Downstream costs include revenue loss, compliance violations, reputational damage, and emergency remediation that typically costs 3–10x more than early intervention would have.
- How is model drift different from model bias?
Bias is a systematic error baked into a model at training time — often reflecting historical inequities in training data. Drift is a post-deployment phenomenon where a previously well-performing model degrades over time. A model can be unbiased at launch and still drift badly, or it can carry bias that worsens as drift compounds it.
Stop guessing.
Start measuring.
Join teams building reliable AI with Trusys. Start with a free trial, no credit card required. Get your first evaluation running in under 10 minutes.
Questions about Trusys?
Our team is here to help. Schedule a personalized demo to see how Trusys fits your specific use case.
Book a Demo
Ready to dive in?
Check out our documentation and tutorials. Get started with example datasets and evaluation templates.
Start Free Trial
Free Trial
No credit card required
10 Min
to get started
24/7
Enterprise support